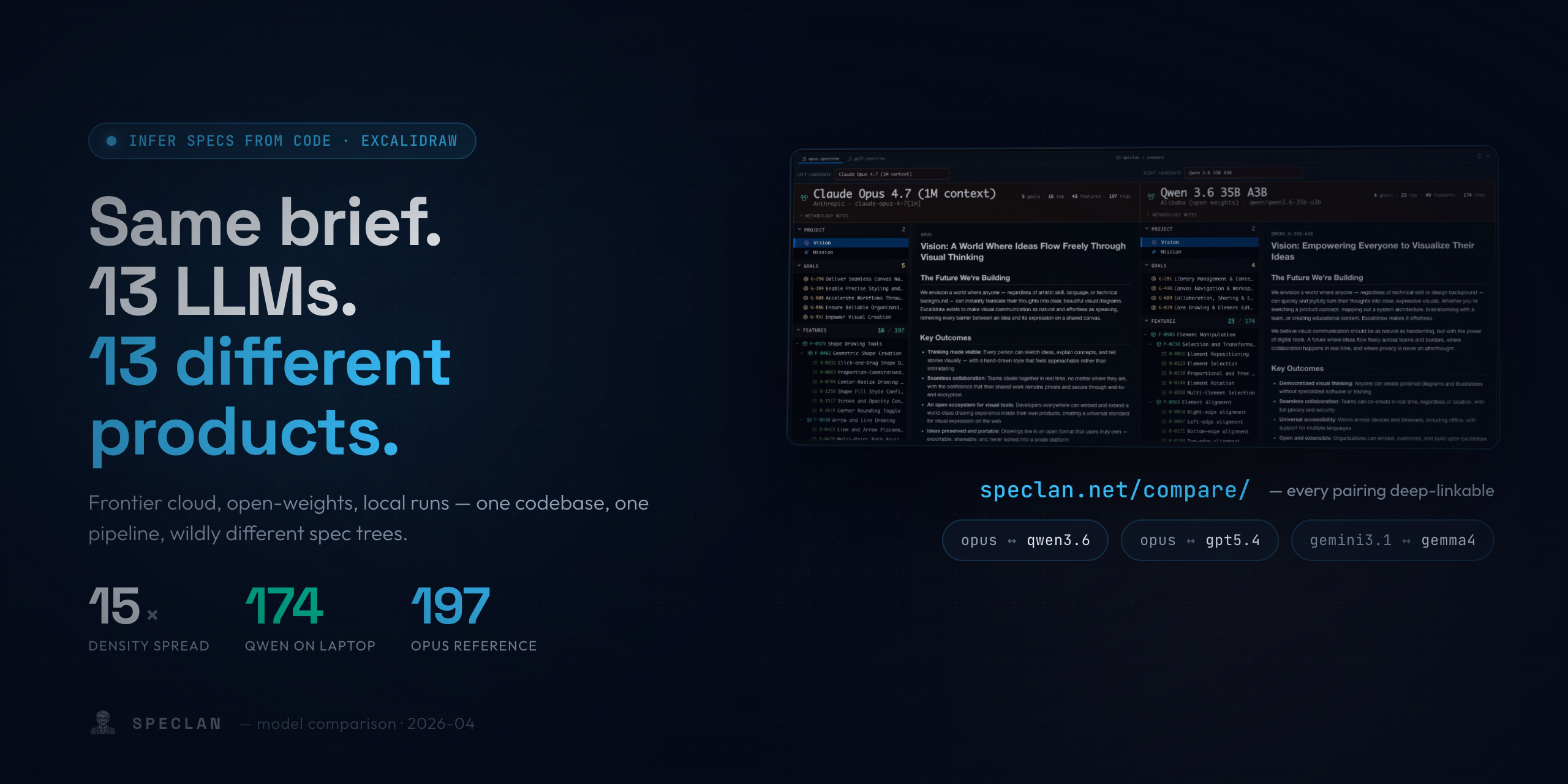
Same Brief. 13 LLMs. 13 Different Products. — A Practical Model-Picking Guide for SDD Teams
We ran SPECLAN's Infer Specs from Code pipeline against the excalidraw codebase with thirteen different LLMs — five frontier cloud models, two Google previews, and six open-weights locals. They produced spec trees that disagree about basic facts: how many features excalidraw has, which framing to use, whether Vision is worth writing down. Requirement density varied 15× on the same code and the same prompt. This is the honest reading of that comparison — what it tells you about picking a model for your own SDD workflow, and three caveats that matter more than any single row in the table.
Why we ran this comparison
Every SDD team we talk to asks the same question within the first week of adopting SPECLAN: which model should I use for my spec work? We have given evasive answers for a year — "it depends," "try a few," "Claude is fine" — because the honest answer requires showing, not telling.
So we decided to show. We pointed SPECLAN's Infer Specs from Code pipeline at excalidraw — one of the most well-understood open-source products on the web — and asked thirteen different LLMs to reverse-engineer the specification from source. Same codebase. Same system prompt. Same MCP tools. Same brief. Only the model changes.
Every resulting spec tree is parked side-by-side at speclan.net/compare/ with URL-sharable deep links. You can send a colleague straight to ?left=opus&right=qwen3.6-35b-a3b and watch them argue over whether "Welcome Screen" is a feature. This post is the honest reading of what that board shows and what we think it means when you have to actually choose a model for your own team.
The setup
Intentionally boring:
- Codebase: excalidraw — infinite canvas, real-time collaboration, exports, AI diagram generation. Widely understood so nobody has to bring domain knowledge to the reading.
- Pipeline: SPECLAN's
Infer Specs from Codeagentic workflow. The LLM is given MCP tools for exploring the repo (read file, list dir, search) plus SPECLAN tools for writing specs (create feature, create requirement, update fields). The pipeline walks the code, decides what features exist, writes them into a goal → feature → requirement tree, and stops when it decides it's done. - Brief: Identical for every model. "Here is the codebase. Produce the SPECLAN spec tree that captures what this product does, from the user's perspective."
- Models: Thirteen candidates — five frontier cloud (Claude Opus 4.7 1M, Sonnet 4.6, Haiku 4.5, GPT 5.4, GPT 5.4 Mini), two Google preview (Gemini 3.1 Pro, Gemini 3.1 Flash), six open-weights run locally (Qwen 3.6 35B A3B, Gemma 4 31B dense, Gemma 4 8B, Gemma 4 26B A4B MoE, GPT-OSS 20B, Nemotron 3 Nano).
Every tree is a full directory of Markdown files under apps/speclan-net/assets/cmp-specs/<candidate>/spectree/. We pre-rendered every entity to HTML at build time, stapled a curator-authored infocard (model, provider, stats, judgement) to each, and shipped the whole thing as a static side-by-side viewer you can pan, resize, and deep-link into.
The numbers
Start with the raw table. Every number is authored by the model itself; we did not touch the trees.
| Model | Goals | Top-level features | Features (nested) | Requirements |
|---|---|---|---|---|
| Claude Opus 4.7 (1M) — reference | 5 | 16 | 43 | 197 |
| Claude Sonnet 4.6 | 5 | 12 | 44 | 196 |
| Claude Haiku 4.5 | 5 | 14 | 45 | 203 |
| GPT 5.4 | 5 | 6 | 23 | 43 |
| GPT 5.4 Mini | 4 | 9 | 23 | 60 |
| Gemini 3.1 Pro (preview) | 3 | 3 | 7 | 17 |
| Gemini 3.1 Flash (preview) | 3 | 3 | 9 | 13 |
| Qwen 3.6 35B A3B (local) | 4 | 23 | 49 | 174 |
| Gemma 4 31B dense (local) | 4 | 5 | 21 | 60 |
| Gemma 4 8B (local) | 3 | 3 | 11 | 21 |
| Gemma 4 26B A4B (local, MoE) | 3 | 4 | 14 | 16 |
| GPT-OSS 20B (local) | 0 | 5 | 16 | 17 |
| Nemotron 3 Nano (local) | 4 | 3 | 6 | 12 |
Two observations that deserve flagging before any interpretation:
Haiku beat Opus on raw requirement count — 203 vs 197. Haiku is the smallest Anthropic model on the table; Opus is the flagship. Haiku produced more by splitting requirements Opus would have kept as one into two or three smaller ones. Whether that's a feature of Haiku or a weakness of the "one requirement per behaviour" instruction is genuinely open.
Qwen 3.6 35B A3B wrote 174 requirements on a laptop. Within 12% of the cloud reference, produced locally via LM Studio with a 50k-token context window on a Mac M4 Max (128 GB unified memory). We did not expect this and we are still a little stunned by it.
Before we read too much into any single row, three caveats have to be named. Two of them are load-bearing on the results.
Caveat 1 — The Anthropic SDK is doing a large share of the work (load-bearing)
If you take one disclaimer from this post, take this one. The comparison is not apples-to-apples, and the asymmetry is large enough that it probably explains more of the density gap than the models themselves do.
SPECLAN's pipeline runs against two different SDK paths, and those paths provide different amounts of agent scaffolding:
- Anthropic SDK (Opus, Sonnet, Haiku) ships a built-in agent loop that includes Todo-List management, planning primitives, and scratchpad memory as first-class tools the model uses alongside our MCP tools. The SDK's defaults wire these in; you opt out, not in. We have not opted out.
- OpenAI SDK (GPT 5.4, GPT 5.4 Mini, Gemini previews through the compatibility layer, and every local OpenAI-compatible endpoint — Qwen, Gemma, GPT-OSS, Nemotron) exposes only our MCP tools. No built-in scaffolding, no Todo-List, no planner, no scratchpad.
The agent tooling the Anthropic SDK ships is not exotic — it's the classic "agent with memory + task list" architecture. The surprise is how load-bearing it turns out to be for spec authoring specifically. Spec authoring is fundamentally a list-management problem (enumerate features, write one, cross it off, move to the next). The SDK solves half of that for you. Without it, every turn the model has to re-derive from conversation history where it is in the enumeration — burning context and decision budget that could have gone into writing better requirements.
The evidence is in the three-model Claude cluster: 196, 197, 203 requirements regardless of model size. Opus is several times the size of Haiku; if model size drove the gap you would see variance. You don't. That flatness is the shape of what the Anthropic agent loop produces — the scaffolding floor, not the model ceiling. Meanwhile every OpenAI-SDK model except Qwen sits in the 13–60 band. An order of magnitude below.
And then there's Qwen 3.6 35B A3B at 174. OpenAI-SDK path, no scaffolding, within 12% of the Anthropic band. Our honest read: Qwen's training mix — heavy on agentic tool-call trajectories — appears to have internalized some of the bookkeeping the Anthropic SDK externalizes as tools. If pure model quality drove the gap, every OpenAI-SDK model would sit at 13–60. Qwen shows the gap is closable without SDK help. That means the gap is about scaffolding, and the scaffolding is reproducible.
For picking a model for your own SDD pipeline, this is the first question to answer: what SDK are you building on, and what scaffolding does it include by default? If your harness is a thin MCP tool-calling loop, your Claude numbers will land much closer to the GPT 5.4 cluster than to the Opus cluster. If your harness ships a Todo-List abstraction — Anthropic SDK, LangGraph, your own — every model underneath it benefits, not just Claude.
On the list: two instrumented Opus runs, one with Anthropic SDK defaults, one with the built-in tools explicitly disabled so Opus runs through the same MCP-only path as the others. The delta isolates the pure-model contribution from the SDK contribution. We'll publish the moment we have it.
Caveat 2 — Excalidraw is in every model's training data
A reader benefit we chose deliberately: you already know what excalidraw does, so you can judge every tree without a domain briefing. An honest cost we have to name: the LLMs also already know about excalidraw. Hundreds of GitHub references, Hacker News front-page threads, dev.to articles, YouTube walkthroughs, the hosted site. Ask any cloud model "what is excalidraw" and it will answer capably without invoking a single tool.
So some fraction of what reads as "the model got this right" is "the model already knew what 'right' looks like." Two pieces of evidence push back against a pure memory-recall hypothesis. The Gemini failure we'll describe next — if pattern-matching-from-memory were the dominant effect, Gemini previews would have produced plausible excalidraw trees from their priors; they produced SaaS scaffolding instead. And the 15× density spread — if models were converging on a training-data consensus, we would see similar trees, not a sixteen-fold range.
For readers applying this comparison to their own codebase, the honest translation: your private codebase is not in anyone's training data. Expect your trees to look worse than what you see on /compare/. Models start from zero priors and have to do the full job through the tools. Requirement counts will drop. Feature naming will be less polished. What generalizes: the structural differences between models — density, decomposition framing, cross-reference behaviour, tool-call termination. What does not generalize: raw output quality.
The follow-up rerun worth doing alongside this one is the same brief against a codebase no frontier model has seen — a days-old open-source project, a synthetic codebase, or an obscure private repo. That tree-shape comparison for the same model separates "model quality on agentic spec-authoring" from "model knowledge about excalidraw." On the follow-up list.
Pattern one — decomposition density varies 15×
Opus and Nemotron 3 Nano received the same codebase and prompt. Opus produced 197 requirements. Nemotron produced 12. A sixteen-fold gap on raw volume.
The shape of the gap is not "more words from bigger models." Gemma 4 8B produced 21 requirements — every one landing on a real excalidraw concept. It is not confused, it is terse. GPT 5.4 produced 43 with top-level features like "Diagram Creation and Editing" that stay at the elevator-pitch level. The ordering is messier than parameter count would predict.
What you see reading the trees side-by-side is the concrete taste of this gap. Opus splits "Shape Drawing Tools" into six drawable element types (geometric shapes, arrows and lines, freehand, text, images, eraser), each with five to seven requirements. GPT 5.4 writes "Shapes, Connectors, and Text" and calls it done with three bullet points. Same functionality, two orders of magnitude of verbosity.
The practical consequence for an SDD team is a taste call that maps onto how you plan to use the spec tree:
- If the tree drives implementation and testing (every acceptance criterion becomes a test case), Opus's density is defensible — sometimes necessary.
- If the tree is an orientation document for a new engineer in week one, GPT 5.4's compression is a feature, not a bug.
- If you want "somewhere in between," Qwen 3.6's 174 requirements with 23 top-level features sits closer to Opus but with slightly finer-grained feature chunking, and costs you electricity instead of tokens.
Pattern two — the framing gap (feature-centric vs user-story-centric)
Some models decompose by what the product does. Others decompose by what the user wants to do. The two framings are not interchangeable, and the resulting trees look almost unrelated at the top level.
Opus, Sonnet, Haiku, Gemma 4 31B, and Qwen 3.6 wrote feature-centric trees: Shape Drawing Tools, Real-Time Collaboration, Export and Import. The product's capability surface, carved into buckets.
GPT 5.4 Mini wrote a user-story-centric tree: Help New Users Get Started, Use The App Offline and Install It, Choose and Detect Language, Share Drawings and Session Links. Same product, decomposed by what a user journey needs to accomplish. This is not a worse tree — for onboarding docs, product marketing, or user-research framing, it is arguably a better one. But it does not map 1:1 against any of the feature-centric trees, which means a side-by-side comparison reads less like "both models said X, Opus said it longer" and more like "we built two different products."
This is one of the most consequential findings for a team adopting SDD. Most "which model is better" discourse assumes models produce noisier-or-cleaner versions of the same underlying decomposition. In practice, different models produce categorically different decompositions, and the decision about which framing is correct for your project is upstream of which model writes well. Agree on framing first. Pick a model that matches it second.
The Gemini anomaly — why the harness matters as much as the model
Google ships two model families we tested. The comparison between them is the sharpest on the board.
- Gemma (open-weights, local via Ollama). Gemma 4 8B produced a coherent on-domain tree — 21 requirements, every one landing on a real excalidraw concept. Gemma 4 31B produced 60 across 21 features.
- Gemini 3.1 (frontier cloud, preview). Gemini 3.1 Flash produced
System Foundation,Data Management Suite,User Identity and Access. Gemini 3.1 Pro producedAccount and Billing Management,Personalized Analytics Dashboard, full acceptance criteria forSubscription tier management (upgrade, downgrade, cancel). Excalidraw has no accounts, no billing, no analytics dashboard.
Same company. Same agentic pipeline on our end. The small local model succeeded at the domain task. The frontier cloud model wrote a different product entirely.
Our working hypothesis: our OpenAI-compatibility shim round-trips tool-call payloads in a format Gemma tolerates but Gemini treats differently. Gemini falls back to training priors when the adapter produces turns it cannot fluently continue — and "enterprise SaaS reference architecture" is over-represented in those priors. Before anyone dismisses the Gemini previews as weak at agentic work, that rerun through Google's native GenerateContent API with planning primitives enabled is on the follow-up list.
The sharper lesson the anomaly forces out: every multi-provider harness silently privileges some providers over others. Our harness privileges Anthropic (full SDK), then accidentally privileges Gemma-like open-weights models (MCP-only works for them). Gemini 3.1 sits in the middle where neither integration fits. The table you read above is thirteen models filtered through a harness that fits some of them better than others. That filter is roughly half of what the comparison is measuring.
If you are building or evaluating an SDD pipeline on multiple providers, ask the same question of your own harness: which provider is this accidentally privileging? The answer is never "none."
Field notes — what the trees reveal that numbers don't
A handful of small observations from reading all thirteen trees front-to-back. None load-bearing alone; together they paint a picture of temperament numbers miss.
- Nemotron 3 Nano produced two identical Goals by accident. Different capitalization, different IDs, different statuses, same topic (
Real-time Collaboration Support). The orientation pass looped and the agent didn't notice it had already written the goal. It also invented an owner namedalice@example.com. Nobody told it there was an Alice. - Gemini 3.1 Pro wrote an entire org chart —
Identity Team,account-team,analytics-team,auth-team— consistent with the SaaS-app fiction its features lived inside. - GPT-OSS 20B wrote the literal string
owner: ?on at least one spec. Self-aware confusion. - Gemma 4 8B assigned work to
automation_bot. Only model that named a bot as a spec owner. - Opus is the only model that wrote cross-references. Its
Real-Time Collaborationfeature spends a paragraph linking out toShape Drawing Tools,Element Styling and Properties,Element Organization,Canvas Navigation and Interaction— explaining which primitives this one operates on. And it writes explicit negative scope fences: "this feature does not provide cloud storage." That is senior-engineer discipline. Nothing else in the lineup does it. - GPT-OSS 20B invented features that don't exist.
QR code creation for quick mobile sharing,Embed widget (iframe) generation,Tracking of link usage (optional audit log). Excalidraw has none of these. The prose reads plausible enough that a reader who doesn't know excalidraw would not catch it. The most dangerous failure mode on the board. - GPT 5.4 Mini wrote a
Help New Users Get Startedfeature. Excalidraw has no onboarding tour. The model inferred one ought to exist and specified it. Product strategy inferred from code, not specification of what's there — useful or misleading depending on your intent.
What we ship with today
Three practical picks we have actually acted on:
- Cloud spec-authoring: Claude Opus 4.7 with the 1M-token context. The reference in the comparison for a reason. Density is high, acceptance criteria are consistent, sub-feature nesting matches how a reviewer would carve the code, and the SDK's built-in planner is the single biggest productivity win we see across providers. Sonnet 4.6 is within 1% of Opus on requirement volume at meaningfully less cost — we reach for it on routine work.
- Local spec-authoring: Qwen 3.6 35B A3B via LM Studio, 50k-token context. Only open-weights model on the table that produces a tree comparable to frontier cloud output. If you have 64 GB+ of unified memory and a spec tree you cannot let leave your machine, this is the working pick. We wrote separately about what changed when we gave SPECLAN a local brain — the behavioural effects are as interesting as the technical ones.
- First-pass exploration on smaller hardware: Gemma 4 8B via Ollama. Not a spec tree to ship, but a fast sketch you can run in the background to see how the pipeline will carve a new repo. Treat it like an outline from a smart intern.
What we do NOT currently use for agentic spec work: any GPT-OSS variant (hallucinates tool-call success and invents scope), any Gemini preview (domain-anchoring issues documented above), the Gemma 4 26B A4B MoE (loop-prone on heavy workflows). None of these are "bad models" — they are models that happen to struggle with the specific agentic demands SPECLAN's heavy workflows place on them. We will re-test when the next generations ship.
A decision framework you can apply to your own team
Read the /compare/ board with three questions in hand, and the model choice tends to fall out of it:
- What framing does my team already share? Feature-centric or user-story-centric. Pick a tree that agrees with how your planning conversations already go. The "right" decomposition is the one your reviewers can navigate without re-learning a taxonomy.
- How will the spec tree be used? Implementation-and-test (favour density, Opus/Haiku/Qwen), orientation (favour compression, GPT 5.4 or Gemma 4 31B), both (Sonnet 4.6 hits a reasonable middle).
- What scaffolding does my harness provide? If you're on Anthropic SDK, your Claude numbers will track the comparison. If you're on a thinner harness, assume your Claude output lands closer to the OpenAI-SDK cluster than to the Anthropic-SDK one — and consider investing in scaffolding (Todo-Lists, planner primitives) before investing in a bigger model.
If you have been wondering whether AI-authored specifications are credible enough to build on, the honest answer the comparison gives is: some of them are, and you can tell which by reading them. Opus's tree reads like a staff engineer's. Qwen's reads like a senior engineer's running late on Friday. GPT 5.4's reads like a smart PM's Monday morning. Nemotron 3 Nano's reads like a prototype. They are all specs. They all came from the same code. The decision about which one to ship with is yours, and it is not primarily a decision about model quality — it is a decision about how you want the product to read.
Try it yourself
Every tree is browsable at speclan.net/compare/. Click a tree node to read the rendered Markdown, drag the divider between tree and text, pick a different candidate on either pane. Every pairing is a shareable URL. Some starting points:
opus ↔ qwen3.6-35b-a3b— frontier cloud vs. the best local model. Close on raw volume, different in feel.opus ↔ gpt5.4— 4.5× density delta between two frontier cloud models.gemini3.1-pro ↔ gemini3.1-flash— the Gemini domain-anchoring pattern in isolation.gemma4-31b ↔ gemma4-8b— dense Gemma at two scales, both on-domain.
The pipeline that produced every one of these trees is Infer Specs from Code in the SPECLAN VS Code extension. It works against cloud and local providers, ships behind a single command, and the local-LLM setup guide is short enough to read over coffee.
For the companion piece on why Qwen 3.6 35B A3B is our current local pick — and what changed about how our own team uses the tool when the model moved to the laptop — read the local-brain post.
We'll publish the instrumented SDK-tools-disabled Opus rerun, the Gemini-through-native-SDK rerun, and the obscure-codebase calibration run as follow-ups. Those are the three experiments that turn this comparison from an honest demo into an honest benchmark.