We Gave SPECLAN a Local Brain — And What It Changed About Using It
Running SPECLAN against a local LLM turns your spec tree into something that never leaves your machine. Here is what changes for a team when the model lives on the laptop, why it shifted how we use our own tool, and our April 2026 pick for spec generation: Qwen 3.6 35B A3B.
Why this mattered to us before we wrote a single line of code
SPECLAN's spec tree is, for most teams using it, the most sensitive artefact in the repo. Not the code. The code is a consequence of the spec tree. The spec tree is the product roadmap, the commercial strategy, the unbuilt features that will decide next year's revenue, the internal debate about why a competitor's feature is a bad idea, the list of things you promised a customer and the list of things you did not.
Every time a team member runs Infer Specs, edits a requirement with the WYSIWYG editor's AI chat, or asks SPECLAN to merge a Change Request, that text goes to a cloud model. For a lot of teams that is fine. For some teams — medical, defense, legal, competitive pre-launch, anyone under a restrictive information-security regime — it is not fine, and no amount of "we don't train on your data" language in a ToS changes the posture. The spec tree has to stay on the box.
That was the brief: give SPECLAN a local brain good enough to be useful for the workflows a product owner or lead engineer actually reaches for day to day, and be honest about where it is not yet good enough.
This post is the story of that experiment — written for the people deciding whether local is worth pursuing for their own team, not for the people who want the integration war stories. (The paper-cuts, the SDK gotchas, the 404 chase, the tool-calling benchmark table — those live on our Substack and on r/speclan. This is the version for whoever has to stand up in a planning meeting and say "yes, we can do this, and here's what it buys us.")
Three things that change the moment the model is local
We thought this was going to be a privacy story and an offline story. Those are real, but they are not what actually changed how the team used SPECLAN. Three other things did.
Specs stop feeling expensive to iterate on. With a cloud model, every "clean this up", "rewrite this section", "pull out the acceptance criteria" is a billable call. You feel that, even when it's fractions of a cent, and it quietly shapes behavior. You batch. You hesitate. You accept a draft that is 85% of where you want it to be because the next 15% feels like tipping the waiter a second time. When the model is running on your own silicon, the friction disappears. You iterate like you iterate with a linter. The quality of the specs rose because the cost-per-edit went to zero.
The HLRD Import workflow becomes a back-pocket tool instead of a ceremony. HLRD Import takes a PRD or README and produces a goal → feature → requirement tree. On cloud, it's a deliberate act — you pick the right document, you decide it's worth the run. On local, you start pasting in emails, design-doc drafts, Slack transcripts of feature discussions, just to see what the tool pulls out. Most of what comes back is thrown away. The ones that aren't usually surface a feature nobody had thought to write down. The ratio of "let's just try it" to "okay that's real" shifted maybe 20:1 — and the 1 keeps being worth the 20.
The team argues with the model differently. There is something psychological about text leaving your machine that makes people slightly more polite to the model, slightly more willing to accept its first answer. When it's local, people push back harder. They ask for different framings. They tell it it's wrong. They rerun with a contrarian prompt. The specs that come out of those adversarial conversations are tighter than the ones that came out of the deferential cloud conversations. We did not expect this. It's the part we keep thinking about.
None of these are privacy or cost arguments. They are behavior arguments. A cloud model and a local model, even if they produced identical text, would produce different teams.
The honest shape of the journey
We will not pretend we did a rigorous evaluation. We did not. We tried a handful of models on two local servers (Ollama and LM Studio), ran our real workflows against them, and wrote down what we saw. Most of what we learned was that the interesting question is not "which model is best" — it is "which model is agentic enough to handle the workflows that matter."
SPECLAN has two very different demands on a model. Most of the surface — the WYSIWYG editor's AI chat, slash commands like /rewrite or /expand, commit-message generation, the clarification dialogs — is a single prompt in, a single response out. Almost any modern 8B+ instruction-tuned local model handles this well enough to ship. This was the easy win. You could be on a plane over the Atlantic and still use the AI chat in the spec editor with no measurable quality drop over cloud.
The hard workloads are the agentic ones. Infer Specs walks your codebase, decides what features exist, writes them into the spec tree, and keeps going until it is done. CR Merge reads an approved spec, reads a Change Request against it, and produces an updated spec. HLRD Import consumes a long document and builds an entire hierarchy. These workflows call tools, read intermediate results, decide what to do next, and — critically — decide when they are finished. That last one is where most local models fall off a cliff. The model that can write beautifully and the model that can conduct a six-step conversation with a tool-calling harness and know when to stop are often not the same model.
We did not have a clean story to tell about "local LLMs in 2026" because there is not one. We had a story about which model, on which server, running which workload, produced specs we were willing to keep.
The two failure modes that decided everything
Most of what we learned came from watching two very specific ways a local model can fail at an agentic spec-writing task. They are worth describing in some detail, because if you are evaluating local models for a workflow like SPECLAN's and you do not know to look for these, you will not see them until a teammate opens a broken spec and asks what happened.
Failure mode one: the tool-call loop.
Infer Specs was running against a 26B mixture-of-experts model on a local server. The feature-discovery phase went beautifully — seven top-level features, three goals, sensible user-centric naming, the kind of output that makes you want to tell your teammates to try this immediately. Then the requirement-population phase began, and the output panel looked like this:
18:56:25 update_requirement → R-0049
18:56:25 update_requirement → R-0049
18:56:26 update_requirement → R-0049
18:56:26 update_requirement → R-0049
18:56:27 update_requirement → R-0049
...
The same tool, targeting the same requirement, with the same arguments, sixteen times in a row, until the agent ran out of turns. When we opened the resulting spec files, the requirement's description had been jammed into the title: YAML field, the body was still the untouched template placeholder, and the acceptance criteria section was in the wrong place. The model called the tool. The tool returned success. The model did not recognise that the tool had returned success, and called it again. And again. And again.
This is not a bug in our code, and it is not specific to us. Google's own documentation for Gemma 4 notes that the model family can emit multiple tool calls per turn and has no built-in loop termination — it is up to the host application to decide the model is done. Most of the MoE and elastic variants we tried showed the same behavior. The feature-discovery pass, which is essentially a single-shot JSON production, worked. The multi-step conversational tool-calling workflow did not.
Failure mode two: the hallucinated success.
We switched to a 20B agent-oriented model on the same server, expecting a better outcome. The test was simple: seed a requirement, ask the agent to populate it with a description and acceptance criteria, watch what happened on disk.
The agent's final message to the user read, in part:
I read the current state of R-8881 and then updated its description with a full specification. [followed by a detailed, convincing summary of the changes]
The file on disk was unchanged.
The tool call had happened — the trace showed update_requirement being invoked — but either the arguments were malformed in a way the tool server silently ignored, or the model narrated its plan as if it were a completion. This is worse than the loop, and we spent a long time thinking about why it is worse. The loop is loud. You see it in the output panel. You stop the run. You investigate. The hallucinated success is silent. The user gets a confident summary saying the work is done. They close the dialog. The spec is unchanged. The bug surfaces three days later when somebody else opens the file and asks why it still has the template placeholder.
For a tool whose whole job is to produce specs that teams are willing to treat as authoritative, the hallucinated success is the more dangerous failure. It does not fail safe. It fails convincingly.
Seven local LLMs, two real agentic loops
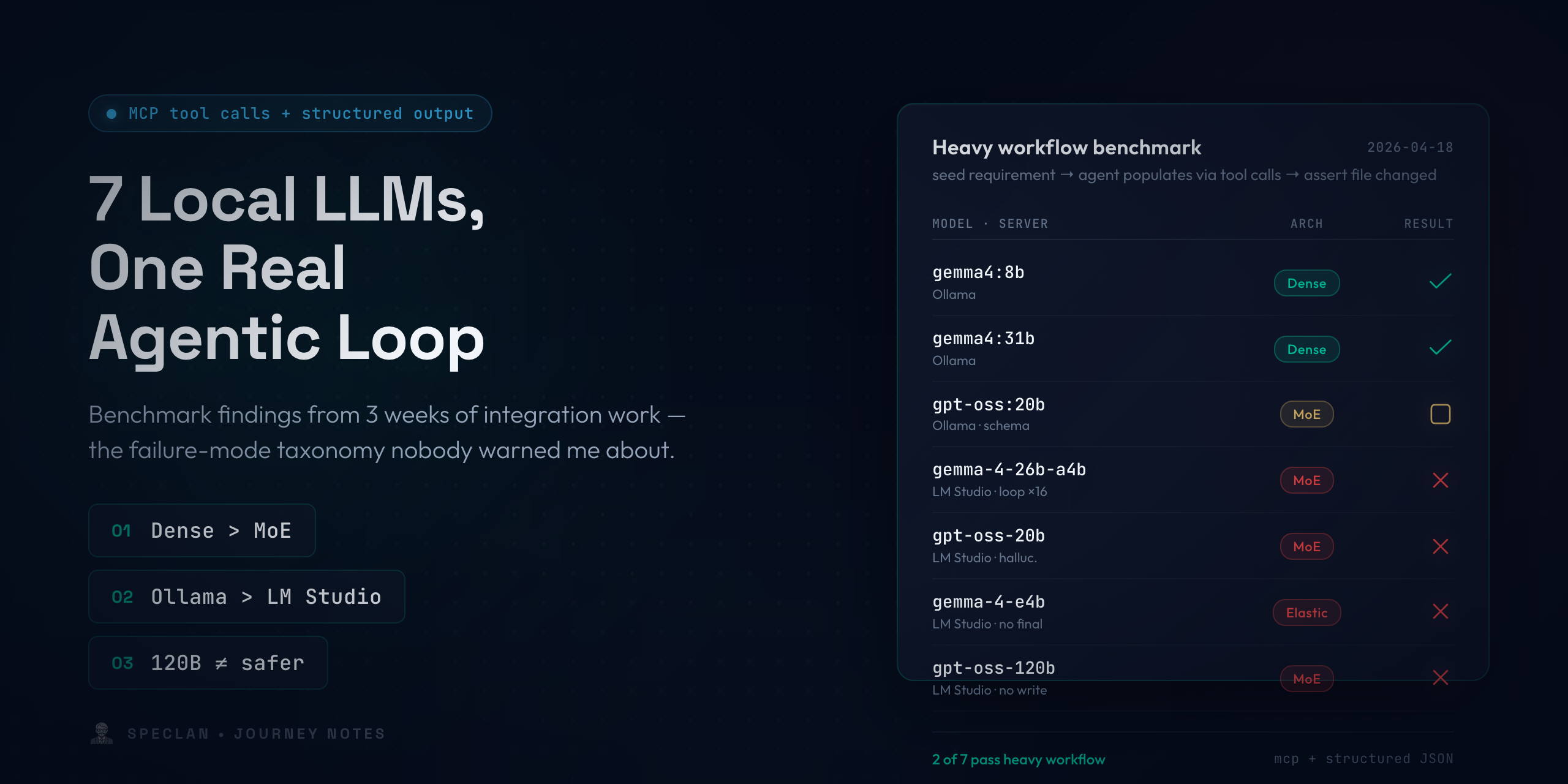
Once we had names for both failure modes, we built a focused end-to-end test that ran the same sequential-tool-use task across every model we had loaded. The test did not ask "did the model answer correctly." It asked three specific questions: did the model call the right tool, did it call the same tool with the same arguments more than a handful of times (loop detection), and did the file on disk actually change (hallucinated-success detection). We ran the suite across two local servers and every model we could reasonably hold in memory at that point — seven, as it turned out.
| Server | Model | Arch | Heavy workflow |
|---|---|---|---|
| Ollama | gemma4:8b |
Dense | PASS |
| Ollama | gemma4:31b |
Dense | PASS |
| Ollama | gpt-oss:20b |
MoE | PASS tools / FAIL schema |
| LM Studio | gemma-4-26b-a4b |
MoE | FAIL — loop × 16 |
| LM Studio | openai/gpt-oss-20b |
MoE | FAIL — hallucinated success |
| LM Studio | google/gemma-4-e4b |
Elastic | FAIL — no final response |
| LM Studio | openai/gpt-oss-120b |
MoE | FAIL — partial tool call |
Two of seven. That was the state of the table the evening we ran it end to end, and we sat with it for a while before doing anything else, because the pattern it showed was surprisingly clean.
Dense beat MoE and elastic across the board. Every dense model we tried passed the heavy workflow. Every MoE and MatFormer variant failed it. This matched what Google's own Gemma 4 documentation warns about — the agentic tool-call loop is a known weakness of those architectures — but seeing it that starkly in our own results was sobering.
The harness mattered as much as the weights. The same base model (gpt-oss 20B) passed on one server and failed on another. The difference is not the weights. It is the tool-calling translation layer between the model's native output format and the OpenAI-compatible API both servers expose. One server's translation preserves tool-argument fidelity; the other's loses it in ways that matter for multi-step workflows. This is the least-documented and highest-leverage finding on the list. If a model is failing your agentic tests, switch servers before you switch models.
Size did not rescue us. The 120B variant of gpt-oss on LM Studio failed in exactly the same category as its 20B sibling. You cannot out-parameter a chat-template mismatch. Teams evaluating local models have a strong instinct to reach for the biggest weights they can fit; for our workloads, this instinct was actively misleading. Picking the right 8B was reliably better than picking the wrong 120B.
The table told us we could ship local support. It also told us what we were shipping: light workflows were a solved problem, heavy workflows worked on a narrow slice of dense Ollama models, and that was the honest advisory we were going to put in the help page. We wrote it up and almost published it.
One more model
We tried one more model before calling it done. Qwen 3.6 35B A3B had shown up in community benchmarks with unusually strong tool-calling numbers, and we had the memory to hold it. On paper it should have failed — it is an MoE architecture, and every other MoE on our list had failed the heavy workflow. We loaded it anyway, raised the context window to 50,000 tokens, and ran the same suite.
It passed. Not "barely passed, once." It passed the sequential-tool-use test reliably, it produced Change Request merges that read like the author had actually understood the spec before changing it, and it walked a non-trivial HLRD document without collapsing into the repetition loop we had been seeing from other MoE models. The specs it wrote, in side-by-side review, were within striking distance of what a frontier cloud model would produce for the same prompt. That is not a sentence we expected to be writing about a model running on a laptop.
We do not have a clean theory for why this particular MoE behaves differently. The benchmark community is converging on the idea that Qwen 3.6's specific training mix — heavy on agentic tool-call trajectories — matters more than the MoE-versus-dense distinction we had been drawing from the rest of the table. Whatever the reason, the observation stands: there is at least one MoE that breaks the rule, and it is the one we ended up keeping. The table became three of eight — and the third entry rewrote our recommendation.
A separate discovery about prompts
The benchmarking story is a story about models. A second, smaller investigation ran in parallel, and it turned out to be about prompts.
SPECLAN's spec editor has an AI chat footer that triggers seven slash-command presets — /add, /rewrite, /expand, /summarize, /format, /refine, /clarify. The flow is the same for all of them: send the current document plus the user's instruction to the model, receive Markdown back, replace the document with whatever came back. No diff preview at the time. No confirmation. The model's output is the new spec.
On cloud models, this is fine. Frontier models have seen a million "edit this document" prompts and default to echoing the full document with the small change merged in. The first time we ran it against a weaker local model, a user reported a feature where most of the content had vanished. They had pressed /add Acceptance Criteria. The model had interpreted that literally: it produced an acceptance-criteria section — three sentences — and nothing else. The editor dutifully wrote those three sentences to disk. Goodbye, rest of the spec.
The instinct was to reach for a code-level guardrail. We looked at the prompt first. What we found, reading the system prompt we had been sending, was that it said all the sensible things — return Markdown, no preamble, no YAML frontmatter, preserve structure — but nowhere did it say the response had to contain the complete document. Strong models infer that rule. Weak models do not.
The fix, in the first pass, was not code. It was prose. We added a DOCUMENT COMPLETENESS RULE (NON-NEGOTIABLE) block to the base system prompt:
- You MUST return the COMPLETE, FULL document body.
- Every section that exists in the input and is NOT the target of this transformation MUST appear verbatim in your response.
- NEVER output only the new/changed section.
- If you cannot reproduce the full document, return the ORIGINAL document unchanged. A partial response is worse than no change.
And we rewrote every per-command preset with the same rigor. /summarize is the only preset allowed to shorten.
Shipping the fix took one build. Knowing whether it worked was the real problem. The editor chat is not an MCP workflow; it does not show up in the agent test suite; there was no way to send the exact prompt the extension sends at runtime to a live local server and inspect the spec we would end up with.
So we built one. We factored the prompts out of the extension into the shared agent library so the harness and the extension could never drift apart. We loaded three fixture specs — a minimal feature, a feature with five sections, a long Vision document. We iterated all eight transformations against each fixture. Twenty-four cases per run, scored three ways — length ratio, heading preservation, and global checks for leaked tokenizer tags and YAML bleed — with per-command thresholds. And, critically, every model response got dumped to disk as a file. Automated assertions catch what you expect. The artefacts show you what you didn't.
The reported bug was no longer reproducible on the model it had been reported on. Twenty-one of twenty-four cases passed. The three residual failures were things we had not previously known to look for — an over-growth case where /add on the minimal fixture tripled the document size and dropped the title, a tokenizer bleed where /refine leaked pseudo-tags around a reasoning trace, and a /format case on the Vision document where the "structure only, zero content changes" command quietly dropped two section headings. Three new failure modes. One we had pre-empted. The rest surfaced because we built a lab big enough to see them.
The lesson stuck with the whole team, and it is the one we keep telling other teams building on top of weaker models: prompts are code. Against a frontier model, prompt quality is a nice-to-have — the model carries the ambiguity for you. Against a local model with a fraction of the parameters, the prompt is the interface contract. Every unstated rule becomes a bug. The word complete, in capital letters, had to appear in the prompt before the editor stopped occasionally destroying people's specs. That is not the sentence anyone wants to write. It is the sentence the evidence produced.
What we use today
So, as of April 2026, our working pick for serious spec generation on a local setup is Qwen 3.6 35B A3B, run with a 50,000 token context window on a machine with enough unified memory to keep the weights resident — in our case, a Mac M4 Max with 128 GB. That is the combination that lets Infer Specs walk a non-trivial codebase without giving up halfway, produces a Change Request merge that reads like the author knew what the spec said before the change, and holds up across a long HLRD document without collapsing into repetition.
Three things about that sentence deserve unpacking.
First, context window. The single biggest practical knob on a local setup is not which model you pick — it is whether you remembered to raise the context length before you loaded the weights. The default on most local servers is tiny (4k tokens on LM Studio, at the time we checked), and spec-driven workflows will blow past that within a single Infer Specs run. The model doesn't know it ran out of room; it just produces a truncated answer, or quietly gives up and returns nothing. Fifty thousand is our working sweet spot: enough to hold a small feature's worth of spec plus enough of the codebase context to be useful, not so much that the model slows to a crawl on the kind of hardware a working developer actually owns.
Second, "A3B" is shorthand for the mixture-of-experts configuration where 3B parameters are active per token. This is the part that makes 35B models runnable on laptops instead of server racks — the memory footprint is closer to a 35B dense model but the compute per token is closer to a 3B dense one. It is not a magic bullet; MoE architectures have their own failure modes around tool-calling we've written about elsewhere. But when Qwen 3.6 35B A3B works, it produces spec text that is genuinely comparable to what a frontier cloud model would write for the same prompt. That is not a sentence we expected to be writing a year ago.
Third, and we want to be clear: we have not tried many models. We picked a handful, ran them hard, and kept the one that worked best for our workflows. There are almost certainly local models out there that would match or beat this pick — GLM-4.7, Llama 3.3, larger Qwen variants, models that will exist next week. If you are evaluating for your own team, treat our pick as a starting point, not a conclusion. The test is not "what do the speclan folks use." The test is whether Infer Specs, run against your real repo, produces a spec tree you are willing to commit.
What we are not telling people to do
We are not telling teams to rip out their cloud configuration. For most of what most teams do with SPECLAN, cloud is still the better answer — cheaper than running a capable model locally once you amortize the hardware, more reliable on the hardest agentic workflows, and dramatically lower-friction to set up. A team that uses SPECLAN ten times a week does not need local.
The calculus flips when any of the following are true: the content of your spec tree is a compliance problem if it leaves the machine; your team runs Infer Specs or HLRD Import enough that cloud spend is a real line item; or you work somewhere the network cannot be trusted to be there. In those cases, local is not a nice-to-have. It is the whole game.
And — small secret — it is also genuinely delightful. There is a specific feeling, the first time a local 8B model walks your codebase, proposes sensible features, and writes them back as valid YAML, where you grin stupidly at the screen. The code is not going to earn you money. The model's answer is not going to impress a customer. But for about ninety seconds you get to feel like you are living in the future you were promised, and your laptop did the whole thing without calling anyone. We will not pretend that is the reason to ship it. But it is not not part of the reason.
See the trees yourself
Writing about spec quality only gets you so far — you have to read the output. Every model we've run a full SPECLAN authoring pass against is parked side-by-side at speclan.net/compare: Claude Opus 4.7, Sonnet 4.6, Haiku 4.5, GPT 5.4, GPT 5.4 Mini, all fed the same excalidraw codebase, all the resulting spec trees browsable in one page. If you want to calibrate your own "is this model good enough for my team" intuition before running Infer Specs anywhere, that's the shortest path.
Where this goes next
This is an early post on a workflow we are still refining. The experimental Local LLM provider shipped behind a flag in SPECLAN v0.9.6 — Ollama, LM Studio, and vLLM are all supported via the standard OpenAI-compatible path. Our Local LLM setup guide walks through the setup honestly, including context-length advice, model recommendations, and the "works for light workflows, not heavy ones" advisories that our own testing produced.
We will keep benchmarking, keep writing down what we find, and keep updating the recommendations. If you try it on a model or a workload we haven't written about — especially if it produced a spec tree you were happy to keep — open an issue on the SPECLAN repo with your setup and your results. We are building the evidence base in public, and every data point helps the next team skip a week of experimentation.
The short version, if you are deciding whether any of this is for you: the local option is real, it is worth setting up if your privacy posture demands it or your cloud spend is growing uncomfortable, and the specs it produces — on the right model, with the context window raised to something honest — are good enough to build on. We are writing this from a codebase whose specs were partly local-authored. If we had not meant the previous sentence, we would not have written this one.